
How to Tune a Teradata System
 Tera-Tom here! Teradata was started back in 1979 with the dream of designing a parallel processing system that could house a Terabyte of data. The experts of the day said that would be nearly impossible and they often reported these facts.
Tera-Tom here! Teradata was started back in 1979 with the dream of designing a parallel processing system that could house a Terabyte of data. The experts of the day said that would be nearly impossible and they often reported these facts.
Think of it like this. If you lived for a million seconds (megabyte) you would live for 11.5 days. If you lived for a trillion seconds (terabyte) you would live for 32,688 years.
Teradata sold their first system, named the DBC 1012, which stands for Data Base Computer 10 to the 12th power (in other words, one trillion).
Teradata’s success has been well-documented. They have 1,400 customers in 77 countries. They also have:
- 18 of the top 20 global commercial and savings banks
- 19 of the top 20 telecommunications companies
- All of the top six airlines
- 11 of the top 20 healthcare companies
- 15 of the top 20 global retailers
- 14 of the top 20 travel/transportation companies
- 13 of the top 20 manufacturing companies
Teradata took the time to ensure that all queries use parallel processing. They came up with a brilliant way to spread the data and retrieve it quickly. They built the system for continued growth and there has always been less of a need for DBAs because Teradata was designed to let the system do most of the work itself.
Teradata systems are also great at loading massive amounts of data. Systems became so large that Teradata was smart to focus on load utilities, so they could load millions of rows extremely quickly. Those load utilities are now part of what Teradata calls TPT. That stands for Teradata Parallel Transport. These load utilities are versatile and exactly what the doctor ordered, but they are also difficult to create unless you are an expert.
What else is brilliant about Teradata is that they use nearly every technique possible for queries to be tuned. There is always good news and bad news. The good news is that Teradata systems can be tuned using dozens of techniques. The bad news is that you need experienced Teradata experts to physically utilize tuning techniques. These systems are not a “load and go” type system like Netezza or Amazon Redshift where there is little tuning needed.
I am going to get you started with the most important fundamentals you need to know to tune a Teradata system. When I say tuning, I mean the many options Teradata provides for creating tables and indexes, sorting and storage in order to make queries run faster. Here is a list of techniques to tune your Teradata system.
The Teradata Architecture
Teradata was born to be parallel, and with each query, a single step is performed in parallel by each AMP. A Teradata system consists of a series of AMPs that will work in parallel to store and process your data. AMPs are told exactly what to do by the Parsing Engine’s (PE) plan. There will be multiple PE’s in a Teradata system with each PE commanding all of the AMPs. The PE is the Teradata Optimizer and it takes user requests and parses the SQL to get the best performance tuning and performance optimization. The PE and AMPs communicate amongst themselves via either BYNET 0 or BYNET 1 and the AMPs write and read data from their disks via the BYNET. The PE and the AMPs work together to keep user’s SQL in check because each user is assigned spool space limits so that if a query goes over its allocated limit the PE will abort the query. This check is vital in case a user accidentally performs a product join, which can result in a runaway query.
Almost every MPP system including Greenplum, Amazon Redshift, Azure SQL Data Warehouse all have these components. They don’t call them the PE and AMPs, but you will hear of a Host instead of a PE and instead of AMPs you have Slices (Greenplum and Amazon), Distributions (Azure SQL Data Warehouse) and SPUs for Netezza. What is important to know is that fundamentally each table created and loaded on a Teradata system is designed so all AMPs own a portion of the data. The more AMPs you have the more powerful the system. A Table can have only one Primary Index (Distribution Key)
A Table can have only one Primary Index (Distribution Key)
Primary Index – A table will designate at least one column to be the Primary Index. This is called the Distribution Key in other systems. This is different than a Primary Key. A Primary Key is used to logically model the tables that join together using a Primary Key/Foreign Key relationship.
A Primary Index is used to physically distribute the rows of a table across the AMPs. A Primary Index is the most important tuning decision there is when creating a table. The primary index column is used when the table is loaded to distribute the rows among the AMPs. When loading the table to the Teradata system, each row will be hashed by a mathematical formula and assigned to an AMP. There are two types of Primary Indexes based on whether or not you want the column to be unique. So, there is the Unique Primary Index (UPI) or the Non-Unique Primary Index (NUPI). This is also a NO PRIMARY INDEX, which means to spread the data rows of a table randomly, but evenly.
The Primary Index is called the Distribution Key in most other system designs, but they are both referred to as the column in the table used to distribute the rows by hashing the value of the primary index column(s). You can have composite primary indexes (up to 64), but each table can have only one primary index. The incredible value here is that anyone who queries the table using the primary index column(s) in their SQL WHERE clause will see SINGLE-AMP RETRIEVE in the query explain plan. A single-AMP will be contacted, and a single block will be placed in memory, and you can depend on getting an answer set in 1-second max, no matter how big the table size.
Since each table will choose a column to be the primary index, the column that becomes the primary index is chosen based on three things:
- How often the column is going to be used in the WHERE clause?
- How often the column is going to be used in the ON CLAUSE of join?
- How well (evenly) will the column distribute the rows among the AMPs?
Believe it or not, the second choice above concerning joins is the biggest consideration. That is because joins can be the most taxing type of query on the system if the two joining tables are not tuned for the join.

A Table can have up to 32-Secondary Indexes
Teradata has Unique Secondary Indexes – Up to 32 secondary indexes can be placed on a table, but each index creates a subtable that takes up space. There are generally two types of secondary indexes. They are the Unique Secondary Index (USI) and Non-Unique Secondary Index (NUSI). The brilliance behind the USI is that all queries that use the USI column(s) in the WHERE clause with an equality statement will be a TWO-AMP RETRIEVE in the explain plan. This means that if you have a huge system with 2,000 AMPs and you query a table with a trillion rows, and you place a WHERE column = a value then only two-AMPs will be contacted, and the query will only take two seconds.
That is one of the greatest assets about Teradata vs. other systems. A Teradata system can have a table that has trillions of rows, but if you use the Primary Index column in your WHERE clause with equality it is a Single-AMP retrieve and it will only take about 1 second. The same goes for a Unique Secondary Index except that it will be a Two-AMP retrieve and only take two seconds. This is because Teradata tables are always sorted and organized. Secondary Indexes are essentially hidden subtables used by the Parsing Engine to point back to the base table. They take up PERM space and they can slow down data loads so use secondary indexes where they make sense. It is also vital that the DBA or the user who owns a table make sure they have performed the Collected Statistic function on all Non-Unique indexes.
Large Tables with Important Date Columns Can be Partitioned
If a large table has a column which has a date or timestamp data type that is queried often with a range query (BETWEEN Statement), the Teradata AMPs can be told to SORT the rows by using a PARTITIONING STATEMENT when creating the table. The DBA team would create a table with partitioning if they noticed or anticipated that users were going to run a lot of range queries on the column. A partitioned table in Teradata is called a Partitioned Primary Index (PPI) table or PPI for short. An example of a PPI table and a SQL statement that uses a range query might be:
SELECT * FROM Order_Table WHERE Order_Date BETWEEN ‘2019-03-01’ AND ‘2019-03-31’;
Each parallel process (AMP) will be involved in the query, but each will only read a portion of the Order_Table rows they are assigned. This is far from a Full Table Scan, and a key to great SQL tuning on large tables. Think of this tuning technique as each AMP having a 12-layer wedding cake that they must eat, but when you can sort the data and only have each AMP eat a slice of cake (data) the speed of this query improves dramatically. The best way to think about partitioning is to imagine that each AMP is sorting the rows like a phone book directory. Now, they won’t have to read through all of the information they have to satisfy a query. Now, each AMP can quickly traverse to the location on their disks where the data for that partition is stored to satisfy queries involving the date column.
All tables and not just columns with important date columns should be considered candidates for partitioning. If it is of an advantage, based on the queries that have been running lately that sorting the data on each AMP for a particular table will speed things up then the table should be partitioned. This usually means that users are running RANGE queries that involve to moments in time or different levels of pricing or different states in a Claims_Table.
You will only see about 10-15% of tables with partitioning.

Tuning Quiz – What are the Four Fastest Queries?
So far you have seen just some of the tuning techniques of a Teradata system, but let me be very clear before we dive into further tuning techniques. The four fastest queries that have the best Teradata performance might surprise you, but they are (from fastest to slowest) when you use indexed columns in the SQL. Below lists the index and how many AMPs will be used (fastest to slowest).
- UPI column – Single-AMP retrieve
- NUPI column – Single-AMP retrieve
- USI column – Two-AMP Retrieve
- All-AMP retrieve by way of a Single-Partition
The All-AMP retrieve by way of a Single-Partition can happen on a Range query (BETWEEN Statement) on a table that has been sorted, in the above example by Month of Order_Date, which is referred to as PARTITIONING a Table. This is done so the AMPs can satisfy queries on large tables without reading through all of the rows. If something is sorted (like a phone book) you don’t have to read through it all in a lot of situations. This type of partitioning technique should really be referred to as Horizontal Partitioning. You will learn next about vertical partitioning.
Columnar Storage (Vertical Partitioning)
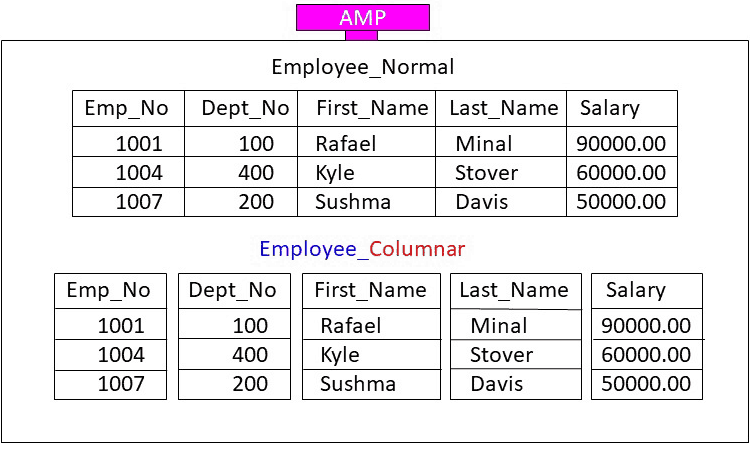
Teradata also has a brilliant way to create a table and have each AMP store the data rows in what the industry calls a COLUMNAR format. This is actually referred to as Vertical Partitioning. Here is exactly what that means. Each AMP will be assigned entire rows, but when the AMP stores the row, they store each column in a separate block so that queries can be satisfied without reading through every portion of a row. Below, the diagram shows a row-based block technique vs the same information stored in a columnar-storage format.
Notice that this AMP has been assigned three rows in the table named Employee_Normal and the exact same three rows in the table named Employee_Columnar. The Employee_Normal example is a traditional storage technique that stores its three rows in a single block. The Employee_Columnar example has the same three rows, but each column is stored in its own data block. Consider it as storing its three rows in five separate blocks.
This is often done on tables where analytics are calculated on just some of the columns. The concept behind a columnar table is that only certain columns from a table need to be read to satisfy a query. It is similar to the tuning technique of PARTITIONING because the concept is applied to tables in order to eliminate having each AMP read all of their data to satisfy a query.
Here is how the theory works. Here is the query:
SELECT AVG(Salary) FROM Employee_Table;
If you ran the above query on the Employee_Normal version each AMP would place their entire block into memory for processing. Even though there is no need for Emp_No, Dept_No, First_Name and Last_Name they are still placed into memory, which is a total waste of effort. This is because an AMP must move the entire block into memory.
However, if you ran the above query example on Employee_Columnar then only the Salary block would move into memory. That is the concept of columnar. The concept of both horizontal partitioning and vertical partitioning is to eliminate moving all of the data into memory. The less data that has to move from disk to memory on each AMP the faster the query.
Intelligent Memory
Teradata systems have an extremely advanced technique for speed with their ability to utilize what is often referred to as an in-memory technique. Each AMP shares nothing with other AMPs because each AMP has their own CPU, memory, operating system and dedicated disk farm. The Teradata system itself will track which data blocks were requested most and then label those blocks as hot. The hottest data blocks are stored in each AMPs dedicated in-memory area.
In other words, when users query for information on data contained in these blocks the queries are performed in sub-second speeds. There is almost no DBA or user intervention required because the system tracks the queries and the data storage in order to determine the hottest blocks and the coldest blocks. The hottest blocks will be kept in memory with the assumption that a ton of users are going to query this particular data. The coldest blocks will be stored on each AMPs slowest disks, which coincidentally are slower and cheaper.
In the diagram below the AMP has FSG Cache Memory, which stands for File System Generating Cache, which really means the AMP’s memory. The important point to notice is the Intelligent Memory. The Intelligent Memory that is given to each AMP is to keep the hottest data blocks they own in Intelligent Memory.
A data block that is placed in Intelligent Memory is the Hollywood celebrity of data because it has been chased by the SQL Paparazzi more than any other data. It is assumed that it will be queried the most so why not keep it in memory until another set of data gets hotter. The difference between FSG Cache (normal memory) and Intelligent Memory is that normal memory has data blocks flying in and out of FSG memory in order for the AMP to be capable to read, update, or delete rows. Intelligent Memory has hot data that stays in the memory all day and maybe even all week. Almost all queries on the intelligent memory are as fast as lightning.

Tuning for Large Table Joins
Here is a life altering learning moment when it comes to big data on systems that have a Massively Parallel Processing (MPP) architecture. Each MPP design has an advantage in that it can scale up continually. This means that you can add data and add AMPs and continue to get linear speeds. As the system gets bigger the customer can purchase more Teradata hardware and scale up to world-record data sizes. The negative to this philosophy or should I say Achilles Heel is that since each AMP has its own dedicated memory, all joining of rows means that joining rows must reside in the same AMPs memory to be joined to satisfy a query. All MPP systems have this same situation.
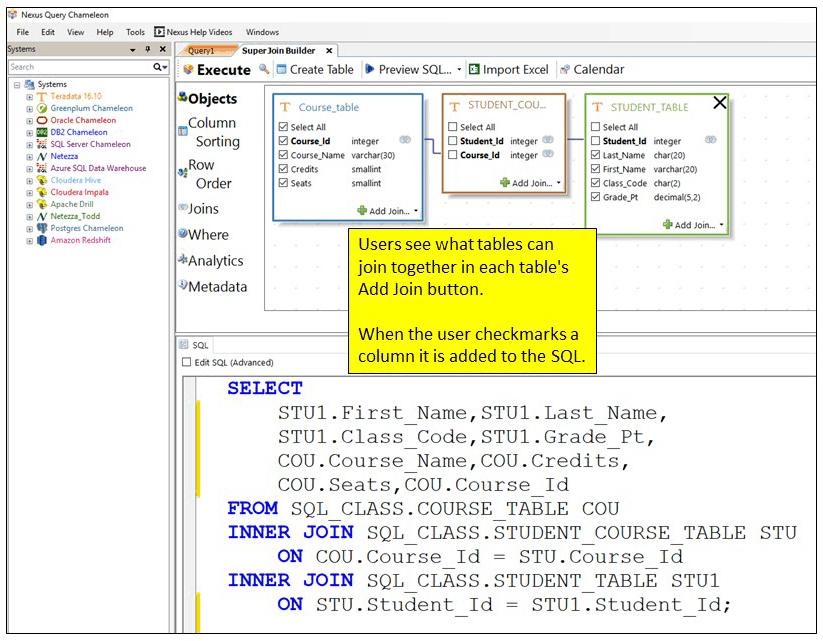
The key to tuning two tables that are being joined together continually is to make the join columns (PK/FK) columns the Primary Index of their respective tables. Below, you can see the Nexus Super Join Builder joining the Customer_Table with the Order_Table. Notice that the columns that both tables have in common is Customer_Number and therefore Customer_Number is the column used in the SQL join condition (ON CONDITION). If the column Customer_Number is used as the Primary Index of both tables, then the matching rows (joining rows from both tables) are already physically on the same AMP. This is called an AMP-Local Join.
Tuning for joins is incredibly important because large tables being joined that have different Primary Indexes than the join condition will cause Teradata (and all MPP systems) to temporarily move the data. For example, if the Customer_Table below had Customer_Number as the Primary Index, but the Order_Table had Order_Number as the Primary Index then Teradata would either temporarily reload the Order_Table by Customer_Number, thus making Customer_Number the temporary Primary Index for just this one join. It literally reloads the Order_Table.
It also can use a different technique if the Customer_Table is much smaller than the Order_Table. The Teradata PE could decide to copy the Customer_Table rows in their entirety and place the entire Customer_Table on each AMP. The bottom line is that all joins must have the matching rows on the same AMP so the most taxing thing for a Teradata system is to have to move data across the BYNET each time to satisfy the join.

Join Indexes
Teradata systems utilize another technique to tune tables that join together often. This is called a Join Index. This is not a temporary table, but a real table that only the Parsing Engine can access. Imagine that you had 1 million rows that are joining from two tables on a consistent basis every day. The DBA team might consider creating a Join Index on the table, which really means that the two tables are joined, and the answer set contains the 1 million joined rows. Now, Teradata stores the answer set rows on the AMPs in parallel distribution so when a user writes this join again the rows are already joined. A Join Index speeds up a join because the rows are already joined and saved and ready to be delivered quickly whenever the join is requested. Think of a Join Index as multiple tables being joined and then stored just like a real table, with each AMP owning a portion of the rows. When the Parsing Engine receives SQL that joins tables and that join can be covered by the Join Index, it commands the AMPs to satisfy the query through the Join Index table. That is also called a “Cover Query”.

Performing Cross-System Joins with Nexus and NexusCore Server
The biggest setback to even the greatest of companies is that different vendor systems don’t talk to one another! So, companies have all of this brilliant data in different silos and analysts are forced to query only one system at a time. This is comparable to having a black and white TV without a remote to change the channel! It makes no sense.
What does make sense is accessing any data at any time. I am talking about cross-system joins, a term referred to as Federated Queries. In order to bring this to fruition, we spent 15 years developing Nexus for the desktop and another two years developing the NexusCore Server.
Nobody else has ever come up with a solution that combines a desktop tool that works in conjunction with a server. Users query from their Nexus on the desktop, but they move data or perform cross-system joins from the NexusCore Server.
With Nexus, users merely point-and-click on any table or view across multiple database platforms and the tens of millions of lines of Nexus code spring into action. Nexus automatically builds the SQL, converts the table structures, moves the data to a central location, joins the data, and returns the answer set.
We have always believed that the perfect tool would do amazingly complicated things for the user. Our end goal was to make Nexus and NexusCore Server so powerful that it makes the business user on the same playing field as the data scientist. With Nexus, a user could write a cross-system join with tables from Teradata, Oracle, SQL Server, DB2 and Greenplum in about 2-minutes. It would take a data scientist a month to get the same results.
Why is it important to have both a Nexus client and a Nexus Server? You want a Nexus client on the desktop so users can query like they normally do. We took it quite a bit further with the Nexus Super Join builder, which writes the SQL for the user. You also need a server component for any data movement or cross-system joins. Why? Because if a user kicks off a data movement job or cross-system join the data that moves goes through the user’s PC. For example, if you were moving data from SQL Server to Teradata the data would move from the source system (SQL Server) to your PC (over the local network) and onto the target system (Teradata). This is what kills the speed, but with the NexusCore Server, the user can run any data movement as if they were sitting on the server. No data moves through the PC or the local network and this can speed things up a 1000%.
It is now less important what systems you store data on because the NexusCore Server can inexpensively move and process data across all systems in the enterprise. Having multiple NexusCore Servers along with thousands of users utilizing the Nexus desktop application make it the perfect environment for cutting edge success.
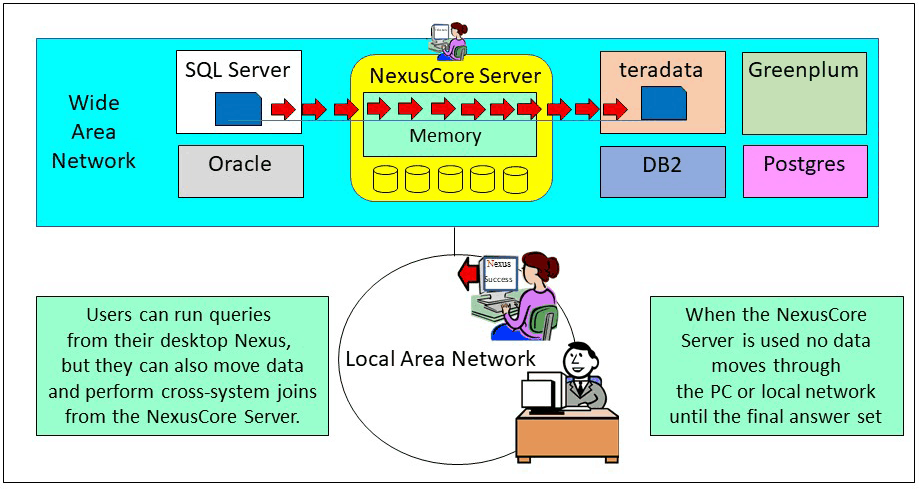
The same thing goes for cross-system joins. It is the NexusCore Server that moves the data to the server, and this provides great speeds. No data goes through the PC or over the local network except the final answer set.

And that is how you tune Teradata! If you ever find yourself needing further information on the inner workings of your Teradata system, you can check out my books or schedule me for a class.
Thank you,
Tera-Tom
Tom Coffing
CEO, Coffing Data Warehousing
Direct: 513 300-0341
Email: Tom.Coffing@CoffingDW.com
Website: www.CoffingDW.com