
The Ultimate Ordered Analytics Lesson
 Tera-Tom Here!
Tera-Tom Here!
I’ll admit it — I had a difficult time learning Ordered Analytics, but once I invested some time, I realized just how easy they are to learn. In this post, I’ll give you the essentials about Ordered Analytics. I won’t cover everything, but you’ll soon be much closer to proficient in understanding the necessary SQL. Practice about a dozen times, and you will be able to write them in your sleep.
Ordered Analytics are named because they are always a two-step process. The first step is to order the data by merely sorting it. Step two is to calculate the requested analytic. This is the future of data analysis and helps customers understand their business with everything from their average order to the conversion rate. Ordered Analytics have been huge for companies who want to enable ecommerce, find trends, and understand how products are performing. Every industry from retail to travel to show business to sports are using Ordered Analytics to give them and edge over the competition.
Rank
The first thing that identifies an Ordered Analytic is the keyword OVER. There is no SQL that uses the word OVER that is not an Ordered Analytic.
The rank in the example below is ranking the Daily_Sales column. This is because of the ORDER BY clause on the column Daily_Sales, which defaults to Daily_Sales ascending. In all Ordered Analytic queries, the rows of the table being queried are first sorted in memory. There is no ORDER BY at the end of an Ordered Analytic because there is always an ORDER BY within the actual analytic statement.
In this case the rows are first sorted by Daily_Sales ASC. That means we are ranking the Daily_Sales. Notice the RANK(). There is never going to be anything inside the parenthesis for the rank command and that is why you look to the ORDER BY to determine the column that is being ranked. Once the rows are sorted, the RANK() command takes over and gives the first row a rank of 1. Notice the tie between rows one and two. Also notice that they both get a rank of 1. Now the third row gets a 3. This is because there was a tie for rows 1 and 2.
If you replaced the keyword RANK() with DENSE_RANK, the only difference is that a tie won’t skip the next number, so the first and second row would get a rank of 1 because they are tied and the third row would get a rank of 2.
Change the RANK() to PERCENT_RANK, and you would see percentages instead of just numbers. Put Rank, Dense_Rank, and Percent_Rank on your next business or ecommerce report and see how excited the analysts become.
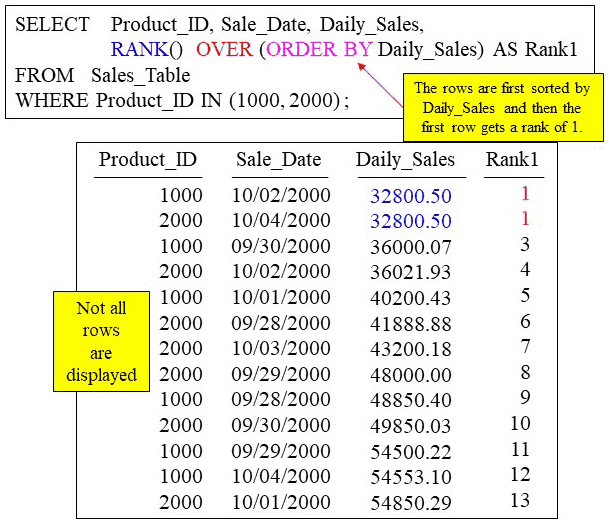
Ranking the Highest Values First
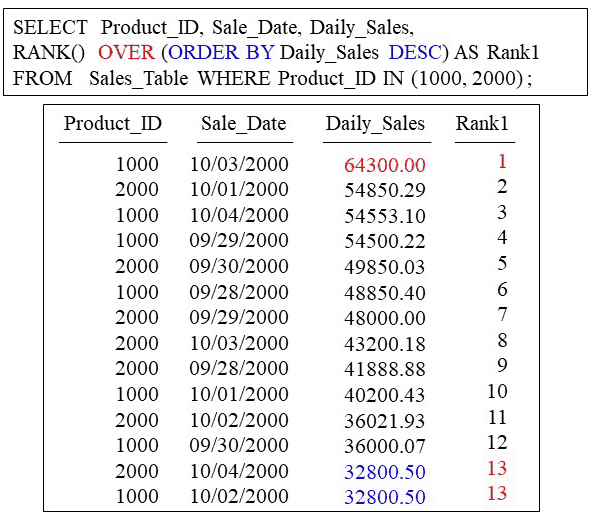
The rank in the example below is also ranking the Daily_Sales column, but this time the ORDER BY Daily_Sales DESC means we are ranking Daily_Sales in descending order (from the highest number to the lowest).
The key to getting great at ordered analytics is to realize that you have the power to sort the data first by ascending order or descending order. In all Ordered Analytic queries, the rows of the table being queried are first sorted in memory. There is no ORDER BY at the end of an Ordered Analytic because there is always an ORDER BY within the actual analytic statement.
In this case, the rows are first sorted by Daily_Sales DESC and that is why we are ranking Daily_Sales. Once the rows are sorted, the RANK() command takes over and gives the first row a rank of 1. Notice the tie between rows 13 and 14. They are tied so they both get the same rank.
Using a PARTITION BY Statement
The keyword PARTITION BY means RESET the CALCULATIONS to start over!
Notice the PARTITION BY Product_ID in the query. Also notice that there is no comma between the PARTITION and ORDER BY. There is only a space. SQL doesn’t care how many spaces you put in, so I put the ORDER BY on the next line. The PARTITION BY Product_ID keywords specify that the RANK should reset for each Product_ID break. This query will rank by Daily_Sales DESC, but perform the ranks separately for each Product_ID.
Anytime you want the calculations to start over when a column changes values you use PARTITION BY. In this case we are ranking the largest to smallest Daily_Sales for Product_ID 1000 and then resetting to rank the largest to smallest Daily_Sales for Product_ID 2000.

Cumulative Sum
At first you might think this query is an aggregate, but then I would have needed a GROUP BY. It is not an aggregate, but instead it is an Ordered Analytic. Why? They keyword OVER.
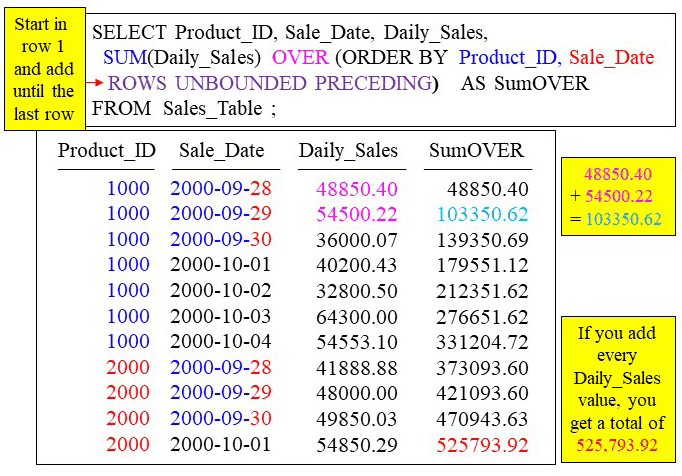
To get a cumulative sum, use the ROWS UNBOUNDED PRECEDING keywords. The data is first sorted by Product_ID and Sale_Date as the major and minor sort. We could have sorted by merely one column, but as you can see from the example below, we can sort by multiple columns.
The first column in an ORDER BY is the major sort and this takes precedence, so the rows are first sorted by Product_ID. The minor sort, Sale_Date, only kicks in when there are ties within the Product_ID. Once the data is sorted the query does a SUM on the Daily_Sales column beginning in row one and continuing on until the last row.
That’s what ROWS UNBOUNDED PRECEDING means. It means sum up the Daily_Sales for row one and then add to that total the Daily_Sales for Row two and continue doing this until you have added up all of the Daily_Sales for all the rows. The very last row will have the total of all Daily_Sales.
There are actually three components here. The first component determines what column to sum, and that is Daily_Sales. The second component determines how the data will be sorted in memory before any calculations take place, which is by Product_ID and Sale_Date (major and minor sorts). The final component is the moving window, which in this case is ROWS UNBOUNDED PRECEDING which means to involve all rows.
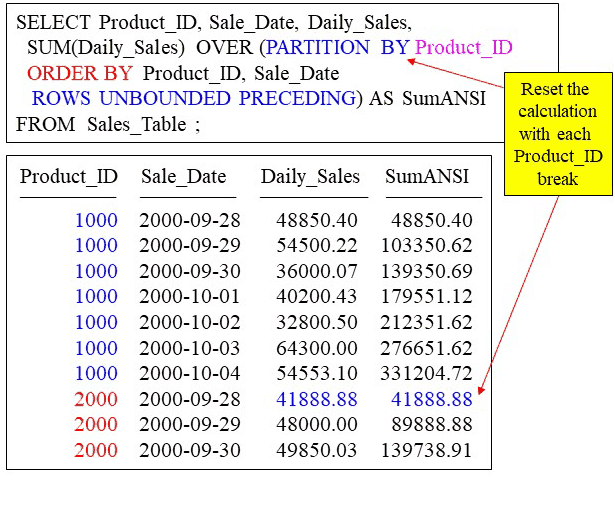
Cumulative Sum that resets with PARTITION BY
By placing the PARTITION BY keywords in front of the ORDER BY we are telling the database to reset the calculations with each Product_ID break. Notice that we are doing a cumulative sum on the rows for Product_ID 1000 and then starting the calculation over when we hit Product_ID 2000.
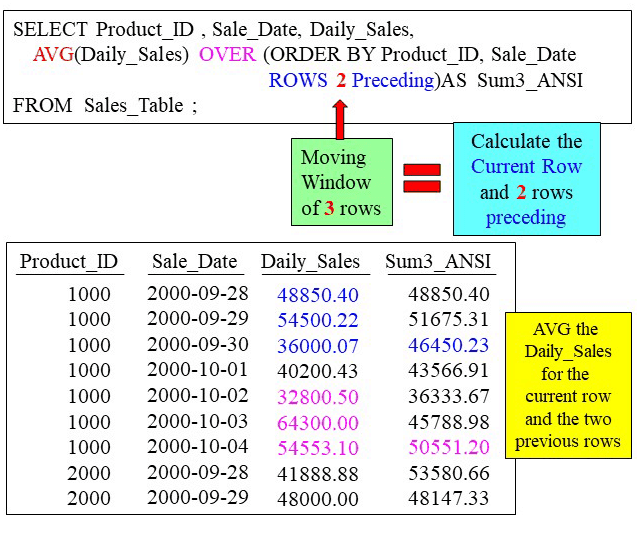
Getting Trending Information with a Moving Average
In the query below we are doing a moving average. This is because of the ROWS 2 Preceding. This query means to AVG the Daily_Sales column after first sorting the rows by Product_ID and Sale_Date (major and minor sort) and then to calculate the average Daily_Sales for the current row plus the two rows preceding.
The ROWS 2 Preceding means we have a moving window of three rows, which translates to averaging the current row of daily sales plus the previous two rows’ Daily_Sales. The first two rows are outliers because the first row can only average row one and the second row can only average rows one and two.
But from the third row on, the calculation is based off of the Daily_Sales value for the current row of Daily_Sales plus the two previous rows’ Daily_Sales. This helps in looking for trends.
Notice the fifth row has the value for our aliased column of Sum3_ANSI of 36,333.67. That is a low watermark for Product_ID 1000 and now the company should investigate further as to why the Daily_Sales were so low for this 3-row calculation.
On the other hand, notice that we had a SUM3_ANSI value of 50551.20, which is the highest 3-row total for Product_ID 1000. The company should also investigate why they did so well during this time period. If you change the word AVG to SUM, you have a Moving Sum.
Using LISTAGG
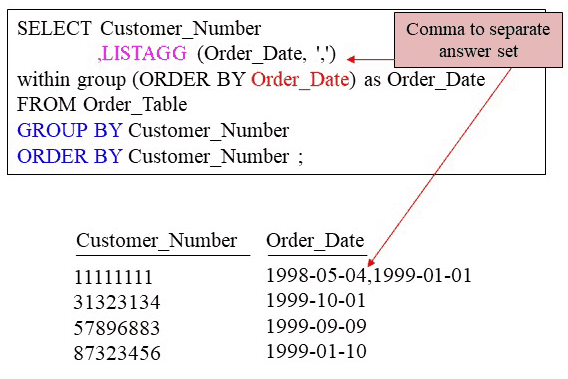
A LISTAGG is a fascinating Ordered Analytic function that doesn’t work on most databases. This works brilliantly on an Amazon Redshift database. Notice the GROUP BY Customer_Number on the second to last line of the SQL. Then notice the LISTAGG(Order_Date, ‘,’). The combination of the GROUP BY Customer_Number and the LISTAGG(Order_Date, ‘,’) means to LIST each Customer_Number on their own line and then show every date the customer placed an order and separate those dates by a comma.
The WITHIN GROUP(ORDER BY ORDER_DATE) tells the LISTAGG to sort the Order_Date on each line by the Order_Date. Notice that Customer_Number 11111111 has placed two orders. Everyone else placed only one order. In the example below, LISTAGG means create a list that aggregates (LISTAGG) all Order_Date values placed by each customer on a single line per customer. One of the greatest usages of this is for website data. Our next example will show how to list the last three web pages a customer visited on a website.
Using the Nexus Garden of Analysis for a LISTAGG
What if your boss asked you to query a table and then build 20 different analytic reports? You would have to query the same table 20 times, and this places unnecessary stress on the database and network.
Why not query the table once and then perform all of the analytic reports inside your PC using the Nexus Garden of Analysis? There is no contention of resources inside your PC! The Nexus Garden of Analysis is like having a database inside your PC that delivers results on all answer sets you have queried today.
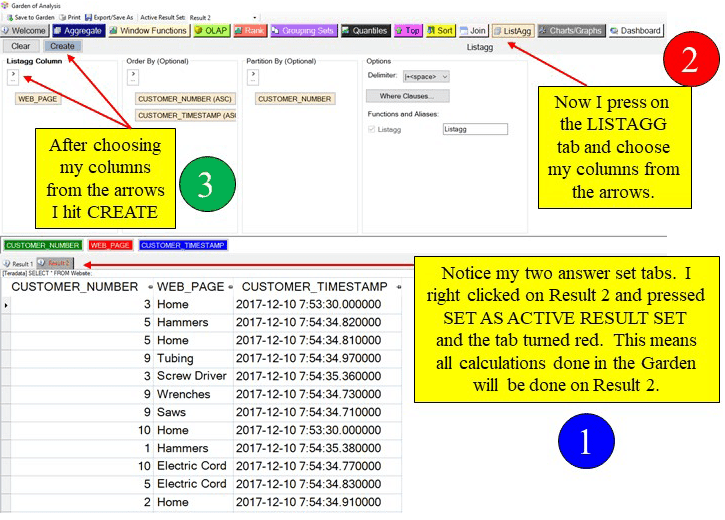
Notice in the screenshot below we have run two queries. Also notice we have two result sets: Results 1 and Results 2. Whenever you get a result set in Nexus it will always be accompanied by a Garden of Analysis tab. Press on the Garden of Analysis tab and watch what happens next. Remember, we have only run two queries today.

Using the Nexus Garden of Analysis for a LISTAGG
When you enter the Garden of Analysis you will see all answer sets you have received. If you ran five queries a piece on three systems, you would have 15 answer sets in your Garden of Analysis.
Right Click on the answer set you want to work with and choose “Set as Active Result Set” from the menu. Then choose a tab from the top. We chose the ListAgg tab. Then use the arrows to fill in the columns and parameters you want. Then hit CREATE and you will see a new report. The screenshot below shows you the steps to follow. We didn’t hit CREATE yet, but look at the screenshot at the end of this blog and you will see the final report.
Getting the New LISTAGG Report
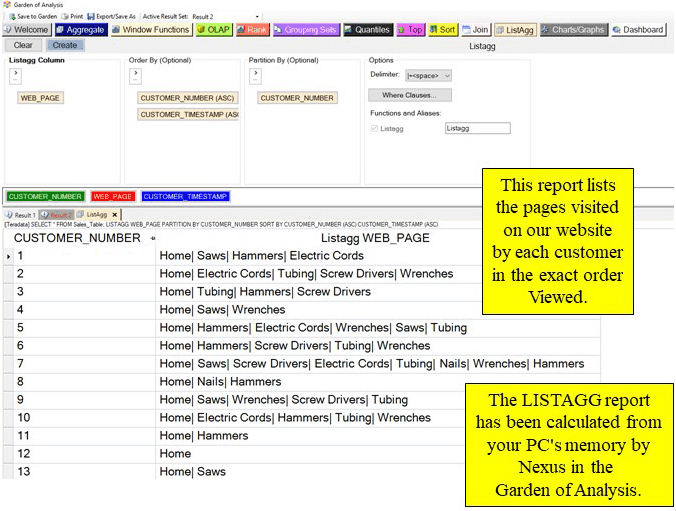
Nexus delivers a new report for LISTAGG that has been calculated by Nexus in the Garden of Analysis. Nexus allows you to get a LISTAGG on any answer set, even if the database you queried originally does not support it. We took all of the analytics we could find and taught Nexus how to calculate them and build the reports. Now, anyone can get advanced analytic reports by choosing the analytic and using the arrows to choose the columns. Below, we see each customer and the exact web pages they visited on our website from step one to the end.
To learn more, check out our books on SQL, Teradata, and more or contact me if you want me to teach an onsite or online class for SQL. You can also download a free trial of Nexus and use the NEXUS HELP VIDEOS to show you all the advanced features.
Thank you,
Tom Coffing
CEO, Coffing Data Warehousing
Direct: 513 300-0341
Email: Tom.Coffing@CoffingDW.com
Website: www.CoffingDW.com