
Yellowbrick Analytics – Part 2 – Ranking Data

I can teach you analytics! I have never seen a database do analytics faster than Yellowbrick. This week we are working on the RANK command.
All of these examples have come from my books and training classes. Please do me a favor and tell your training coordinator that you know the best technical trainer in the World. Ask them to hire me to train at your company, either on-site or with a virtual class. They can see our classes, outlines, and a sample of my teaching at this link on our website. I hope to meet you and say thanks in my next class at your company:)
https://coffingdw.com/education/
In each example, you will see an ORDER BY statement, but it will not come at the end of the query. The ORDER BY keywords is always within the RANK calculation. It is the ORDER BY statement that determines what we are ranking.
In its most simple explanation, a RANK will sort the data first via the ORDER BY statement, and then give the first row a ranking of 1. It will rank the second row with a two unless the value of row one and row two are equal. Check out the example below.
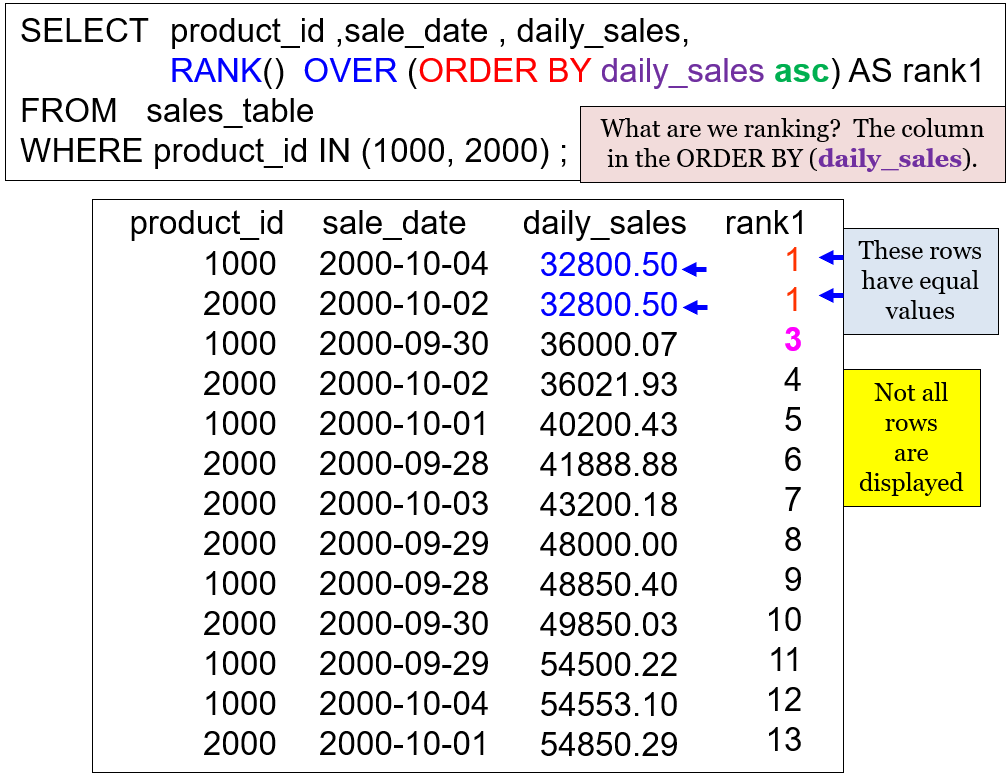
In the picture above, notice that an open and close parenthesis immediately follows the keyword RANK. The open and close parenthesis insinuates a function. There is never anything inside the parenthesis, but it is required. The keyword OVER follows, which represents that this analytic is an ordered analytic, which is interchangeable with the term window function. The term ordered analytic means that the data set will be put in a specific order before the calculation begins. We sort the data using the ORDER BY statement, and in this example, we are sorting by the daily_sales column. Since the default for an ORDER BY statement is ascending, we are ranking the data by daily_sales ASC.
When you first see a RANK command with nothing in the parenthesis, you might have trouble at first and think, “What are we ranking?” Just check out the column in the ORDER BY statement, and that is what you are ranking. We have an ORDER BY daily_sales, so we are ranking by daily_sales.
The first two rows both have a value of 32,800.50, so they both get a rank of 1. Rows one and two are tied, but notice that row three receives a rank of 3. There are no more ties after that, so each row gets the next sequential ranking.
Quite often, a user will want to give the highest value the number one rank. Check out the example below because we are going to use the ORDER BY to rank the daily_sales column in DESC order.
The phrase below sounds like a protest chant:
What are we ranking? daily_sales!
How are we ranking it? Descending order!

Each RANK example will have an ORDER BY statement, but sometimes you will also have a PARTITION statement. In the example below, you see the keywords PARTITION BY, and that means the RANK function will reset and start the calculation over. Our ORDER BY statement is ordering the data by the column daily_sales DESC, so daily_sales is what we are ranking. Still, we will reset the rank calculation and start over with each product_id break because the column product_id is in the PARTITION BY statement. Check out the next example below.

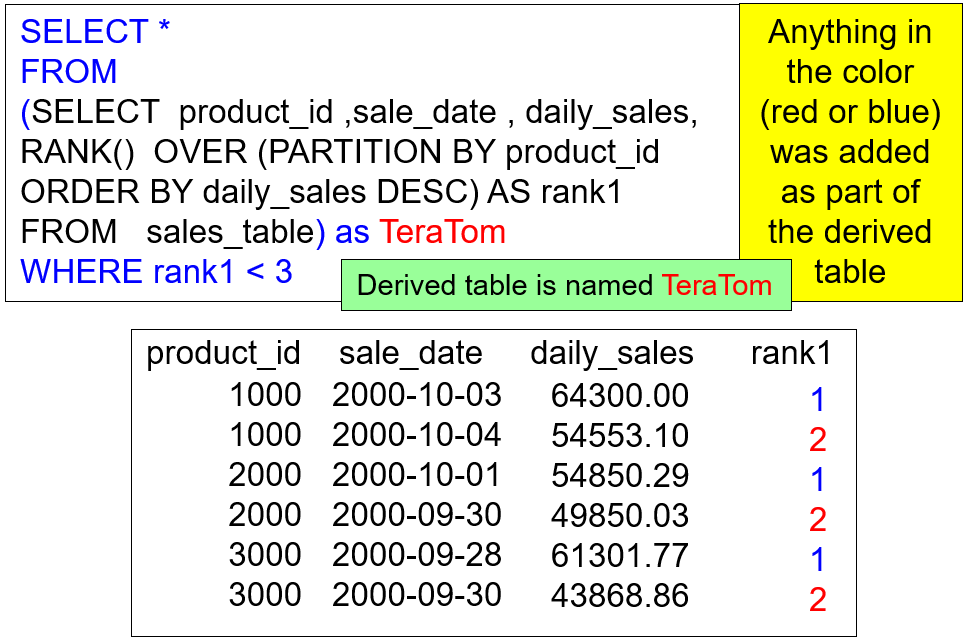
Sometimes you only want calculations that meet certain requirements, so you often use a WHERE clause. If you want the certain requirements on the analytic functions, you need to put them in a derived table. This is because the calculations have not been calculated yet. When you place the analytic query in a derived table, the derived table populates with the calculated results. You can then select from the derived table to find the requirements you need. In the example below, all of the SQL using the color blue and red is part of the derived table.
In the next two examples below, we are attempting to find the top two ranking products (daily_sales) for each product_id (1000, 2000, 3000). We build the analytic in a derived table named TeraTom, and then we select from TeraTom. Since the calculations are complete the WHERE clause works.
The example below is the same query as the picture above, but we are using another derived table technique. This technique creates the derived table first, but it then requires you to run another SELECT statement and query from the derived table.

You are about to see something not often seen, and that is the DENSE_RANK. It works exactly like the RANK command, but RANK and DENSE_RANK handle ties differently. In our example below, we are using both the RANK and DENSE_RANK functions. Since both of them have the same ORDER BY daily_sales statement, the data comes out the same, with the only difference being how they handle the ties. The first two rows get a rank of one since they both tie with a value of 32,800.50. The RANK gives the third row a ranking of three, and the DENSE_RANK gives it the third-row a ranking of two.

The example below shows the PERCENT_RANK function. Percent_Rank finds out the relative rank of a row in a group. The formula to get Percent_Rank is
(RANK-1 / (Total Rows -1).

Did you know that Coffing Data Warehousing is the first company to create software that joins data across all systems? Download your free Nexus trial at www.CoffingDW.com.
Watch how the Nexus performs federated queries. Watch the video.
I hope you enjoyed today’s Yellowbrick analytic lesson. See you next week.
Thank you,
Tera-Tom
Tom Coffing
CEO, Coffing Data Warehousing
Direct: 513 300-0341
Website: www.CoffingDW.com or http://www.CloudNexusSaaS.com
YouTube channel: CoffingDW
Email: Tom.Coffing@CoffingDW.com